
Hallo Spaß-Coder,
heute möchten wir mal mit einem Bilderrätsel anfangen. Was assoziiert ihr im Zusammenhang mit Code-Qualität mit dem folgenden Bild?

Grüne Wiese, Freiheit, Möglichkeiten, alles aber auch alles Erdenkliche hier zu erbauen. Ist es nicht so?
Wie oft aber findet ihr eher folgendes in der Realität vor?

Einen Haufen Schutt und Müll, unsaubere Strukturen und ein Chaos, in welches ihr nun eine neue Funktion, ein neues Feature implementieren sollt. Wie schön wäre es doch, immer auf der grünen Wiese arbeiten zu können, oder?
Genau deshalb schreiben wir hier diese ganzen Blog-Artikel. Angefangen bei den Basics über die SOLID-Prinzipien, bis hinzu agilen Methoden. Wir wollen, guten Code und wir wollen, dass auch ihr guten Code schreiben könnt und wollt.
In diesem Artikel werden wir darauf eingehen, wie ihr schlechten Code erkennen könnt. Dabei spielt es keine Rolle, ob ihr den Code vorfindet und ändern müsst, oder selbst geschrieben habt.
Das Schlüsselwort dazu lautet Code-Smells. Teile unseres Codes, der den Prinzipien widerspricht oder schlecht wartbar und damit fehleranfällig ist. Wenn unser Code also anfängt zu riechen, wird es Zeit, für ein Refactoring.
Fokus: Einfachheit
Das Wichtigste Vorweg. Im Umfeld der agilen Softwareentwicklung ist Einfachheit ein wichtiger Faktor. Das Prinzip dahinter lautet KISS: Keep it simple, stupid.
Zu deutsch bedeutet es je nach Lesart: Halte es einfach, dumm oder Halte es einfach, Dummerchen.
Dieses Prinzip sollten wir uns bei allem was wir entwickeln immer vor Augen halten. Verlieren wir langsam den Überblick, wird es zu kompliziert oder haben wir nun zum 3. Mal angefangen, die Methode zu lesen, wird es Zeit für eine Pause. Tretet einen Schritt zurück und überdenkt nochmal, was ihr eigentlich erreichen wollt und ob es wirklich so kompliziert sein muss.
Ein Spaziergang durchs … Grüne … hilft hierbei oft, den Kopf frei zu bekommen…manchmal reicht es aber auch, sich einen Kaffee zu holen.
Sehr große Klassen
Klassen, die sehr viele Zeilen Code haben, wiedersprechen wahrscheinlich dem Single Responsibility Principle. Ein Beispiel, welches wir an andere Stelle schonmal gebracht haben ist die Klasse Playfield aus einem Spiel, welches wir mal fertiggestellt haben. Die Klasse hat stolze 987 Zeilen, 52 Methoden und 19 Klassenvariablen. Sich hierin zurechtzufinden ist nicht leicht. Und ja, die Klasse macht im Grunde nur Sachen mit dem Playfield. Aber was genau? Naja, alles halt.
Es gibt keinen Richtwert, wie groß eine Klasse idealerweise sein sollte. So ab 100 Zeilen sollte man aber schonmal einen näheren Blick auf die Klasse werfen, ob hier nicht doch zu viel passiert.
Sehr große Methoden
Was für Klassen gilt, gilt in gleicher Weise für Methoden. Bei Methoden sollte es dem Leser möglich sein, auf einen Blick zu sehen, wo die Methode beginnt und wo sie endet. Es sollte deutlich werden, was in der Methode passiert.
Das Wichtigste ist aber, dass eine Methode sich möglichst nur auf einem Detaillevel bewegen sollte. Es sollte also nicht Konzepte verschiedener Detailstufen miteinander vermischen.
Auch hier ein Beispiel aus dem o.g. Spiel. Die Methode CheckAndRemoveLines() umfasst 82 Zeilen (davon 2 Kommentarzeilen). Sie durchläuft zunächst das Playfield Zeile für Zeile, führt Prüfungen gemäß eines gewissen Regelsatzes durch und entfernt dann ggf. Objekte aus dem Playfield. Anschließend erfolgt das gleiche für Spalten. Das Verarbeiten der Zeilen (und Spalten), das Prüfen und das Entfernen der Objekte sind alles unterschiedliche Detailebenen in der Gesamtlogik. Dass sie in einer Methode implementiert sind, führt zu einer langen und unübersichtlichen Methode. Das diese nicht gut testbar ist, sei hier nur am Rande erwähnt.
Derartige Methoden sollten aber leicht vermieden werden können, wenn ihr euch auch für Methoden an das Single Responsibility Principle haltet. Eine Methode, die nur genau eine Aufgabe erfüllt, kann nicht sonderlich groß werden.
Namensgebung
Über gute Namen haben wir bereits im Artikel Basics – Aussagekräftige Namen gesprochen. Warum das auch ein Code-Smell ist? Nun, Klassen mit dem Namen Manager, Utils und Helper neigen dazu, mit allem möglichen gefüllt zu werden. Wir brauchen eine kleine Methode, die uns bei der Verarbeitung von Strings hilft? Dann legen wir doch eine Klasse StringHelper an und schreiben die Methode da rein. Brauchen wir eine weitere Hilfsmethode, kommt sie ebenfalls in StringHelper. Sie tut aber ggf. was ganz anderes. Ja, beide Methoden arbeiten mit Strings, aber sie haben völlig verschiedene Zwecke.
Wir haben also bei diesen beiden Methoden zwei Gründe, die Klasse zu ändern (wenn sich die Anforderung an eine der beiden Methoden ändert). Das ist ein klarer Verstoß gegen das Single Responsibility Principle und führt – vor allem in Teams – zu doppelten Implementierungen, weil wir aufgrund der schlechten Namensgebung schwer eine Funktion in einem großen Projekt finden. Stattdessen schreiben wir lieber unsere eigene Implementierung…natürlich in einer eigenen Klassen namens StringHelper. Nein, bitte nicht.
Ein Beispiel aus den o.g. Spiel. Hier gibt es einen Namespace Helper mit einer Klasse SpielHelper.
|
1 2 3 4 5 6 7 |
internal static Vector2 ToVector2(Vector3 vector)... internal static Vector3 ToVector3(Vector2 vector)... internal static Vector2 CalculateGemPositionInWorld(Vector2 positionInPlayfield)... internal static void PlaySound(string soundName)... internal static Sound GetSound(string soundName)... internal static Vector2 GetGemPositionFromIndex(int index, int width)... internal static int GetTimeElapsedSinceLastFrameInMillis()... |
Was macht die Klasse? Sie lädt Sound-Dateien, wandelt 3-dimensionale Vectoren in 2-dimensionale um, berechnet Positionen und führt Zeitmessungen durch. Kurz: alles Mögliche, wir haben wohl keinen besseren Platz dafür gefunden. Schade auch.
Alle unsere Klassen helfen uns, nicht nur diejenigen, die Helper im Namen tragen. Zeugen wir ihnen also den gebührenden Respekt und benennen sie passend.
Ein weiterer Punkt, an dem man erkennen kann, dass eine Methode vielleicht mehr als eine Aufgabe übernimmt ist, wenn „and“ im Namen vorkommt. Das Beispiel von oben: CheckAndRemoveLines() Was macht die Methode? Genau, sie prüft und entfernt Zeilen. Das sind offensichtlich zwei Aufgaben. (Tatsächlich entfernt sie nichtmal Zeilen sondern Objekte vom Playfield…der Name ist also auch noch falsch).
Methodenparameter
Was durch das Wort „and“ über den Namen erfolgt, kann genauso über einen boolschen Parameter ausgedrückt werden. Eine Methode, die einen Parameter vom Typ bool erhält, wird mit großer Wahrscheinlichkeit mehr als eine Aufgabe haben. Hier erneut ein Beispiel aus der o.g. Klasse Playfield:
|
1 2 3 4 5 6 7 8 9 10 11 |
public void Update(bool handleInput) { if (handleInput) { HandleInputIfNoGemIsMoving(); } else { ... } } |
So ein Konstrukt sieht man häufig, wenn boolsche Parameter verwendet werden. Wenn true mach dies, sonst das. Das ist wieder ganz klar mehr als eine Aufgabe.
Zu unserer Entschuldigung sei gesagt, dass diese Methode von der von uns verwendeten Game-Engine so vorgeschrieben war…aber bei der Klasse helfen eigentlich keine Entschuldigungen mehr 😮
Auch die Anzahl der Parameter einer Methode sind ein Hinweis auf Code, der ein wenig riecht. Die besten Methoden erhalten keinen Parameter. Sie beziehen sich komplett auf die Klassenvariablen. Methoden mit einem oder zwei Parameter sind noch in Ordnung. Ab drei Parametern sollte man langsam darüber nachdenken, ob man die Methode – oder ggf. das gesamte Design drumherum – nicht nochmal überdenken sollte.
Regions in C#
In C# gibt es Regions. Regions bilden in C#-Code Blöcke, die keine Funktionalität haben, sondern einfach nur einen Bereich im Code gruppieren, der dann eingeklappt werden kann. Hier nochmal das Beispiel Playfield:
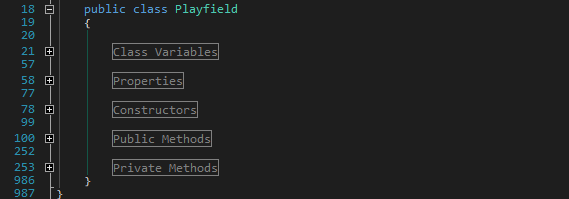
Und da soll nochmal einer sagen, die Klasse sei unübersichtlich…
Aber im ernst. Wenn ihr geneigt seid, Regions zu verwenden, um die Übersicht über den Code zu behalten, denkt besser über eine Aufteilung der Klasse in kleinere Bestandteile nach.
Dependency Injection
Hier ist erstmal nur wichtig zu wissen, dass es dabei um Abhängigkeiten einer Klasse geht, die von außen mitgegeben werden können.
Der Code-Smell hier ist die Anzahl der Dependencies. Wenn viele Abhängigkeiten injected werden oder viele Parameter an den Konstruktor übergeben werden (Constructor-Injection), deutet das darauf hin, dass die Klasse zu groß ist und zu viele Aufgaben hat.
Schaut euch die Abhängigkeiten genau an. Müssen diese wirklich alle sein, um den eigentlichen Zweck der Klasse zu erreichen?
Lange Ableitungshierarchien
Der letzte Punkt, auf den wir heute eingehen möchten, ist eine sehr lange Kette von Ableitungen. Klassen, die voneinander abgeleitet sind, haben naturgemäß eine sehr enge Kopplung zueinander. Muss an einer der beteiligten Klassen eine Änderung durchgeführt werden, ist oft die ganze Ableitungskette betroffen. Dies führt dazu, dass die Klasse ohne Grund geändert werden muss, nur weil eine der Elternklassen eine Änderung erfahren hat.
Daher ist Komposition häufig einer Ableitung vorzuziehen (Composition over Inheritance). Zusammen mit dem Open-Closed-Principle schaffen wir so ein lose gekoppeltes Design, dass leicht erweiterbar ist.
Zusammenfassung
Wenn man gerade so schön dabei ist, den Code zu schreiben und endlich das Erfolgserlebnis hat, dass er funktioniert (Yeah!), übersehen wir leicht, wie viel Dreck wir doch hinterlassen haben. Oft liegt an jeder Ecke Müll herum, die schöne grüne Wiese, auf der wir begonnen haben, ist zu einer kleinen Müllhalde geworden.
Wenn wir hier nicht gleich aufräumen, wird das immer schlimmer. Ein Grund ist, dass wir natürlich viel lieber das nächste Feature machen, als aufzuräumen. Aber vielleicht kennt das er ein oder andere aus seiner Kindheit (oder ihr beobachtet es bei euren eigenen Kindern): Nach dem Spielen die Spielsachen wegzuräumen macht einfach keinen Spaß, also lassen wir sie liegen. Nun haben wir eine Stunde Zeit zum Spielen, bevor die Hausaufgaben dran sind…davon verbringen wir dann 45 Minuten damit, die Spielsachen zu suchen, mit denen wir spielen wollen. Nach dem wir sie gefunden haben, bleiben uns noch 15 Minuten.
Auch die Theorie der Broken Windows verstärkt noch, dass unser Code immer schwerer lesbar wird.
Alles in allem führt sauberer Code dazu, dass wir wirtschaftlich entwickeln können. Wenn wir erst stundenlang den Code verstehen müssen, ewig nach Hilfsmethoden suchen oder schon wieder eine Klasse nicht wiederverwenden können, weil sie mehrere Aufgaben erfüllt, sind wir nicht sehr wirtschaftlich. Und Spaß macht das auch keinen.
Räumt also immer auf und verlasst den Code immer ein wenig sauberer, als ihr ihn vorgefunden habt. Dann riecht das hier auch nicht mehr so.
Viel Spaß beim Ausprobieren und Happy Coding wünschen
eure Spaß-Coder
Dieser Artikel basiert neben unseren Erfahrungen auf den Ausführungen aus:
- Martin, Robert C. Clean Code-Refactoring, Patterns, Testen und Techniken für sauberen Code: Deutsche Ausgabe. MITP-Verlags GmbH & Co. KG, 2013.
-
Fowler, Martin Workflows of Refactoring.
OOP 2014 - Hariri, Hadi Refactoring Legacy Code Bases
Basta Sprint 2013
Die ersten beiden Bilder stammen von http://www.freeimages.com